Приведение произвольной матрицы к форме Хессенберга
Применяя отражения Хаусхолдера, мы можем привести любую матрицу к форме Хессенберга
U^* A U = H
Единственное отличие от разложения Шура состоит в том, что мы должны отобразить первый столбец в вектор с двумя ненулевыми элементами, причем первый элемент не изменяется.
Вычислительная сложность такого приведения составляет \mathcal{O}(n^3) операций.
В форме Хессенберга вычисление одной итерации QR алгоритма требует \mathcal{O}(n^2) операций (например, используя вращения Гивенса, как?), и форма Хессенберга сохраняется при QR итерации (проверьте почему).
Симметричный (эрмитов) случай
В симметричном случае у нас A = A^*, тогда H = H^* и верхняя форма Хессенберга становится трехдиагональной матрицей.
Далее мы будем говорить о случае симметричной трехдиагональной формы.
Любая симметричная (эрмитова) матрица может быть приведена к трехдиагональной форме с помощью отражений Хаусхолдера.
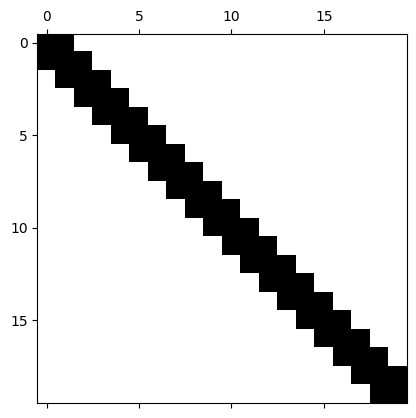
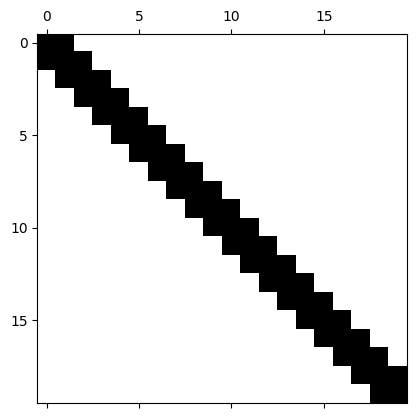
Ключевой момент заключается в том, что трехдиагональная форма сохраняется при QR алгоритме, и стоимость одного шага может быть снижена до \mathcal{O}(n)!
QR алгоритм: итерации
Итерации QR алгоритма имеют следующий вид:
A_k = Q_k R_k, \quad A_{k+1} = R_k Q_k.
Если A_0 = A является трехдиагональной симметричной матрицей , эта форма сохраняется при QR алгоритме.
Давайте посмотрим..
%matplotlib inlineimport numpy as npimport matplotlib.pyplot as plt#Generate a random tridiagonal matrixn =20rng = np.random.RandomState(0)d = rng.normal(size=(n,))rng = np.random.RandomState(1)sub_diag = rng.normal(size=(n-1,))mat = np.diag(d) + np.diag(sub_diag, -1) + np.diag(sub_diag, 1)mat1 = np.abs(mat)mat1 = mat1/np.max(mat1.flatten())plt.spy(mat)q, r = np.linalg.qr(mat)plt.figure()b = r.dot(q)b[abs(b) <=1e-12] =0plt.spy(b)#plt.figure()#plt.imshow(np.abs(r.dot(q)))b[0, :]
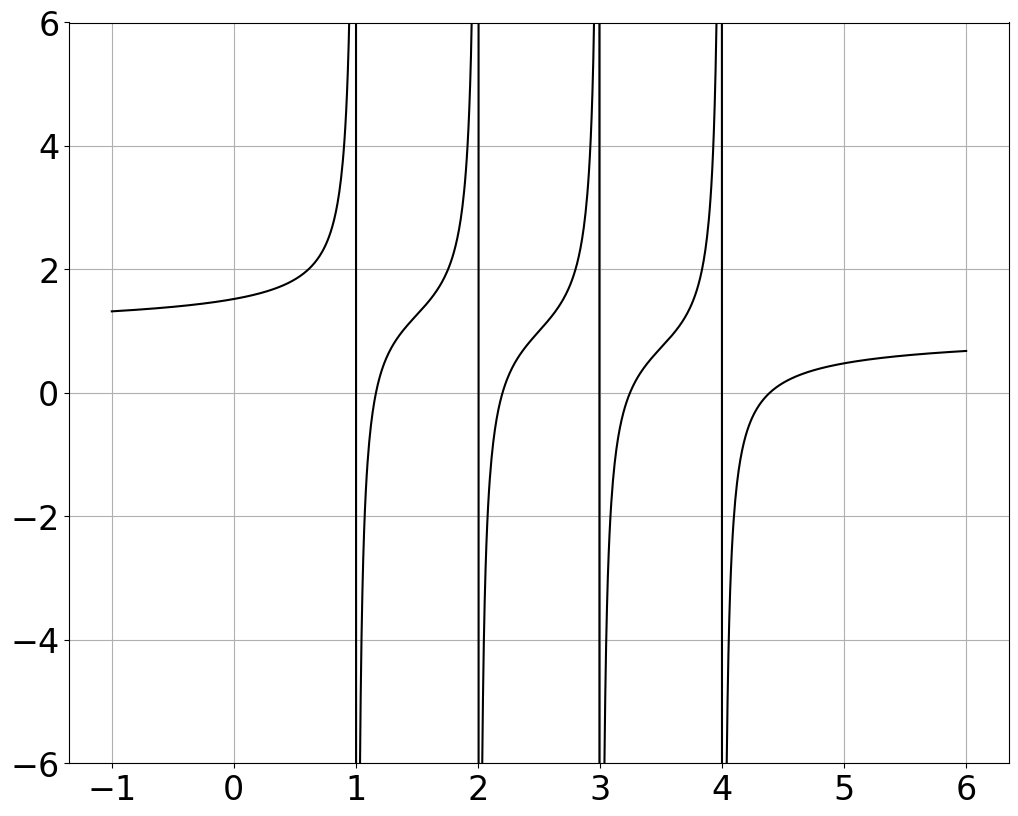
и существует разрыв между собственными значениями \Lambda_1 и \Lambda_2 (|\lambda_1|\geq \dots \geq |\lambda_m| > |\lambda_{m+1}| \geq\dots \geq |\lambda_r| >0), тогда блок A^{(k)}_{21} матрицы A_k в QR-итерации стремится к нулю со скоростью
где \lambda_m - m-е по величине собственное значение матрицы по модулю. - Если сдвиг близок к собственному значению, то скорость сходимости лучше. - Существуют различные стратегии выбора сдвигов. - Введение сдвигов - это общая стратегия для улучшения сходимости итерационных методов нахождения собственных значений. - В следующих слайдах мы проиллюстрируем, как выбрать сдвиг на более простом алгоритме.
Сдвиги и степенной метод
Вспомним степенной метод для вычисления собственных значений.
x_{k+1} := A x_k, \quad x_{k+1} := \frac{x_{k+1}}{\Vert x_{k+1} \Vert}.
Он сходится к собственному вектору, соответствующему наибольшему по модулю собственному значению.
Сходимость может быть очень медленной.
Попробуем использовать стратегию сдвигов. Если мы сдвигаем матрицу как
A := A - \lambda_k I
то соответствующее собственное значение становится маленьким (а нам нужно большое). - Это не то, что мы хотели!
Метод обратной итерации и метод итерации Рэлея
Чтобы сделать малое собственное значение большим, нам нужно обратить матрицу, и это дает нам метод обратной итерации
x_{k+1} = (A - \lambda I)^{-1} x_k,
где \lambda - сдвиг, который является приближением к собственному значению, которое мы хотим найти.
Как и для степенного метода, сходимость является линейной.
Для ускорения сходимости можно использовать метод итерации Рэлея (обратная итерация с адаптивными сдвигами), который задается выбором адаптивного сдвига:
x_{k+1} = (A - \lambda_k I)^{-1} x_k,
\lambda_k = \frac{(Ax_k, x_k)}{(x_k, x_k)}
В симметричном случае A = A^* сходимость локально кубическая, а в остальных случаях - локально квадратичная.
Сингулярные значения и собственные значения (1)
Теперь поговорим о сингулярных значениях и собственных значениях.
SVD
A = U \Sigma V^*
существует для любой матрицы.
Это также можно рассматривать как приведение данной матрицы к диагональной форме с помощью двусторонних унитарных преобразований:
\Sigma = U^* A V.
С помощью двусторонних преобразований Хаусхолдера мы можем привести любую матрицу к бидиагональной формеB (как?).
Сингулярные значения и собственные значения (2)
Неявный QR алгоритм (со сдвигами) дает способ вычисления собственных значений (и формы Шура).
Но мы не можем применить QR алгоритм непосредственно к бидиагональной матрице, так как она не диагонализируема в общем случае.
Однако задача вычисления SVD может быть сведена к задаче о собственных значениях симметричной матрицы двумя способами:
Работать с трехдиагональной матрицей
T = B^* B
Работать с расширенной матрицей
T = \begin{bmatrix} 0 & B \\ B^* & 0 \end{bmatrix}
Случай 1 хорош, если вы не формируете T напрямую!
Таким образом, задача вычисления сингулярных значений может быть сведена к задаче вычисления собственных значений симметричной трехдиагональной матрицы.
Алгоритмы для задачи о собственных значениях симметричных матриц
Рассмотрены: - QR алгоритм: “золотой стандарт” вычисления собственных значений
Следующие слайды: - Метод “разделяй и властвуй” - Метод бисекции - Метод Якоби
Разделяй и властвуй
Предположим, у нас есть трехдиагональная матрица, и мы разделяем ее на два блока:
T = \begin{bmatrix} T'_1 & B \\ B^{\top} & T'_2 \end{bmatrix}
Мы можем записать матрицу T как
T = \begin{bmatrix} T_1 & 0 \\ 0 & T_2 \end{bmatrix} + b_m v v^*
где vv^* - матрица ранга 1, v = (0,\dots,0,1,1,0,\dots,0)^T.
Это показывает линейную сходимость метода. При этом локально (вблизи решения) сходимость становится квадратичной.
Jacobi: итоги
Метод Якоби был первым численным методом для вычисления собственных значений, предложенным в 1846 году.
Большая константа
Очень точный (высокая относительная погрешность для малых собственных значений)
Хорошие возможности параллелизации
Итоги по этой части
Множество алгоритмов для вычисления решения задачи на собственные значения:
QR
Разделяй и властвуй
Метод бисекции
Метод Якоби
Следующая лекция
Мы начинаем разреженную и/или структурированную численную линейную алгебру.
Questions?
from IPython.core.display import HTMLdef css_styling(): styles =open("./styles/custom.css", "r").read()return HTML(styles)css_styling()
---------------------------------------------------------------------------FileNotFoundError Traceback (most recent call last)
Cell In [2], line 5 3 styles =open("./styles/custom.css", "r").read()
4return HTML(styles)
----> 5css_styling()
Cell In [2], line 3, in css_styling() 2defcss_styling():
----> 3 styles =open("./styles/custom.css","r").read()
4return HTML(styles)
File ~/miniconda3/envs/tensorflow/lib/python3.9/site-packages/IPython/core/interactiveshell.py:282, in _modified_open(file, *args, **kwargs) 275if file in {0, 1, 2}:
276raiseValueError(
277f"IPython won't let you open fd={file} by default " 278"as it is likely to crash IPython. If you know what you are doing, " 279"you can use builtins' open." 280 )
--> 282returnio_open(file,*args,**kwargs)FileNotFoundError: [Errno 2] No such file or directory: './styles/custom.css'