Концепция итерационных методов для линейных систем: - Итерация Ричардсона и её сходимость - Итерация Чебышева
Итерационные методы
Если мы хотим достичь сложности \mathcal{O}(N) при решении разреженных линейных систем, то прямые решатели не подходят.
Если мы хотим решить частичную задачу на собственные значения, полное разложение на собственные значения слишком затратно.
Для обеих задач мы будем использовать итерационные решатели подпространств Крылова, которые рассматривают матрицу как линейный оператор по принципу черного ящика.
Матрица как черный ящик
Теперь у нас совершенно другой взгляд на матрицу: матрица теперь линейный оператор, который действует на вектор,
и это действие может быть вычислено за \mathcal{O}(N) операций.
Это единственная информация, которую мы знаем о матрице: произведение матрицы на вектор (матвек)
Можем ли мы решать линейные системы, используя только матвеки?
Конечно, мы можем умножать на столбцы единичной матрицы и восстановить полную матрицу, но это не то, что нам нужно.
Итерация Ричардсона
Самая простая идея - это “метод простой итерации” или итерация Ричардсона.
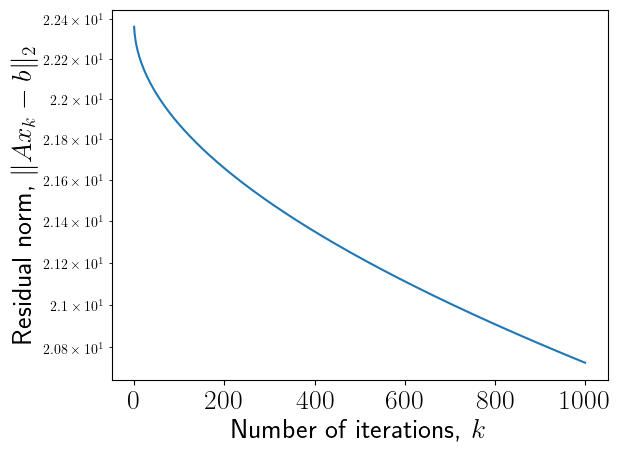
import numpy as npimport matplotlib.pyplot as plt%matplotlib inlineplt.rc("text", usetex=True)import scipy as spimport scipy.sparseimport scipy.sparse.linalg as splaimport scipyfrom scipy.sparse import csc_matrixn =500ex = np.ones(n);A = sp.sparse.spdiags(np.vstack((-ex, 2*ex, -ex)), [-1, 0, 1], n, n, 'csr');rhs = np.ones(n)ev1, vec = spla.eigsh(A, k=2, which='LA')ev2, vec = spla.eigsh(A, k=2, which='SA')lam_max = ev1[0]lam_min = ev2[0]tau_opt =2.0/(lam_max + lam_min)fig, ax = plt.subplots()plt.close(fig)niters =1000x = np.zeros(n)res_richardson = []for i inrange(niters): rr = A.dot(x) - rhs x = x - tau_opt * rr res_richardson.append(np.linalg.norm(rr))#Convergence of an ordinary Richardson (with optimal parameter)plt.semilogy(res_richardson)plt.xlabel("Number of iterations, $k$", fontsize=20)plt.ylabel("Residual norm, $\|Ax_k - b\|_2$", fontsize=20)plt.xticks(fontsize=20)plt.yticks(fontsize=20)print("Maximum eigenvalue = {}, minimum eigenvalue = {}".format(lam_max, lam_min))cond_number = lam_max.real / lam_min.realprint("Condition number = {}".format(cond_number))#print(np.array(res_richardson)[1:] / np.array(res_richardson)[:-1])print("Theoretical factor: {}".format((cond_number -1) / (cond_number +1)))
Maximum eigenvalue = 3.99984271815512, minimum eigenvalue = 3.932084756989659e-05
Condition number = 101723.207035276
Theoretical factor: 0.9999803389964071
Таким образом, для плохо обусловленных матриц ошибка метода простой итерации убывает очень медленно.
Это еще одна причина, почему число обусловленности так важно:
Помимо оценки погрешности решения, оно также дает оценку количества итераций для итерационных методов.
Главный вопрос для итерационного метода - как сделать матрицу лучше обусловленной.
Рассмотрим неэрмитову матрицу A
Возможные случаи поведения итерации Ричардсона: - сходимость - расходимость - почти стабильная траектория
Вопрос: как мы можем определить наш случай до запуска итерационного метода?
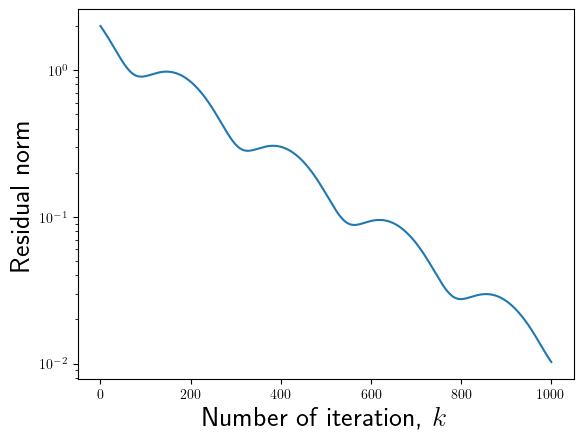
# B = np.random.randn(2, 2)B = np.array([[1, 2], [-1, 0]])# B = np.array([[0, 1], [-1, 0]])x_true = np.zeros(2)f = B.dot(x_true)eigvals = np.linalg.eigvals(B)print("Spectrum of the matrix = {}".format(eigvals))# Run Richardson iterationx = np.array([0, -1])tau =1e-2conv_x = [x]r = B.dot(x) - fconv_r = [np.linalg.norm(r)]num_iter =1000for i inrange(num_iter): x = x - tau * r conv_x.append(x) r = B.dot(x) - f conv_r.append(np.linalg.norm(r))
Spectrum of the matrix = [0.5+1.32287566j 0.5-1.32287566j]
plt.semilogy(conv_r)plt.xlabel("Number of iteration, $k$", fontsize=20)plt.ylabel("Residual norm", fontsize=20)
Text(0, 0.5, 'Residual norm')
plt.scatter([x[0] for x in conv_x], [x[1] for x in conv_x])plt.xlabel("$x$", fontsize=20)plt.ylabel("$y$", fontsize=20)plt.xticks(fontsize=20)plt.yticks(fontsize=20)plt.title("$x_0 = (0, -1)$", fontsize=20)
Text(0.5, 1.0, '$x_0 = (0, -1)$')
Улучшенные итерационные методы
Но прежде чем перейти к предобуславливателям, мы можем использовать улучшенные итерационные методы.
Существует целый зоопарк итерационных методов, но нам нужно знать лишь некоторые из них.
Попытка 1: Метод наискорейшего спуска
Предположим, что мы меняем\tau на каждом шаге, т.е.
x_{k+1} = x_k - \tau_k (A x_k - f).
Возможный выбор \tau_k - такой, который минимизирует норму текущего остатка
Последнее неравенство является единственным приближением. Здесь мы делаем ключевое предположение , что мы не хотим извлекать выгоду из распределения спектра между \lambda_\min и \lambda_\max.
Таким образом, нам нужно найти многочлен такой, что p(0) = 1, который имеет наименьшее возможное отклонение от 0 на [\lambda_\min, \lambda_\max].
Многочлены, наименее отклоняющиеся от нуля (2)
Мы можем выполнить аффинное преобразование интервала [\lambda_\min, \lambda_\max] в интервал [-1, 1]:
Он имеет (n+1)точек альтернанса, где достигается максимальное абсолютное значение (это достаточное и необходимое условие для оптимальности) (теорема об альтернансе Чебышёва, доказательство здесь не приводится).
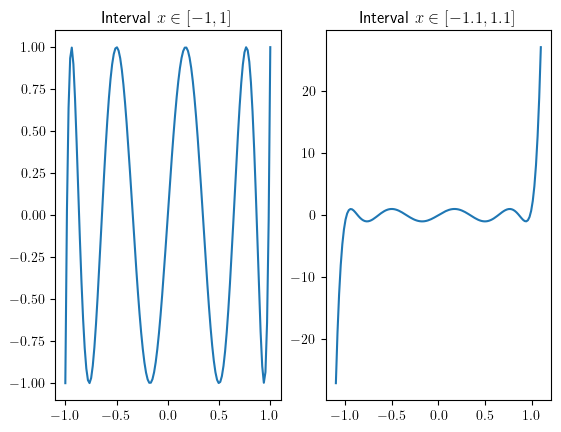
import numpy as npimport matplotlib.pyplot as plt%matplotlib inlinex1 = np.linspace(-1, 1, 128)x2 = np.linspace(-1.1, 1.1, 128)p = np.polynomial.Chebyshev((0, 0, 0, 0, 0, 0, 0, 0, 0, 1), (-1, 1)) #These are Chebyshev series, a proto of "chebfun system" in MATLABfig, (ax1, ax2) = plt.subplots(1, 2)ax1.plot(x1, p(x1))ax1.set_title('Interval $x\in[-1, 1]$')ax2.plot(x2, p(x2))ax2.set_title('Interval $x\in[-1.1, 1.1]$')
Text(0.5, 1.0, 'Interval $x\\in[-1.1, 1.1]$')
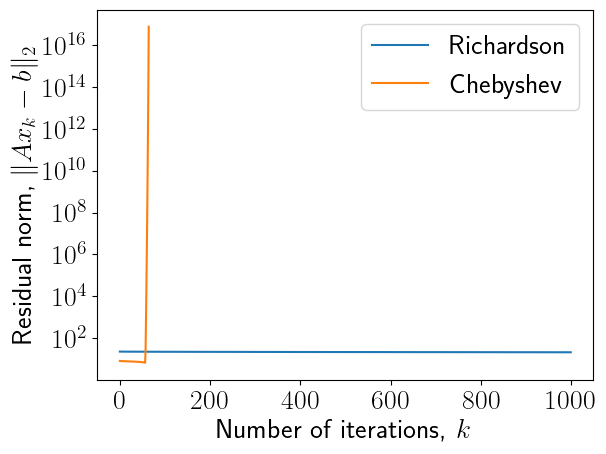
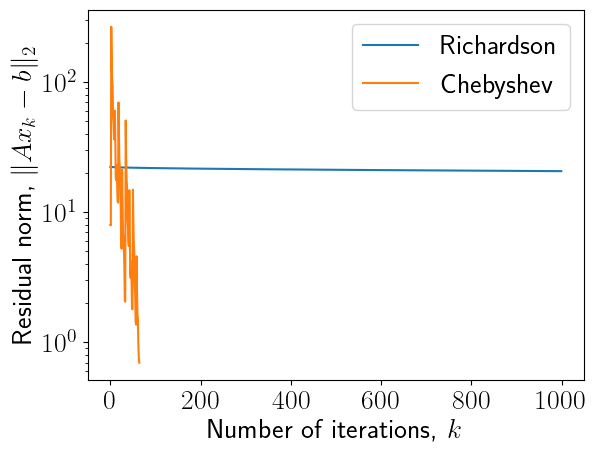
Сходимость метода Ричардсона с ускорением Чебышёва
Заметим, что p(x) = (1-\tau_n x)\dots (1-\tau_0 x), следовательно, корни p(x) равны 1/\tau_i, и нам дополнительно нужно отобразить интервал [-1,1] обратно в [\lambda_\min, \lambda_\max]. Это приводит к формуле
Что случилось с замечательными итерациями Чебышева?
niters =64roots = [np.cos((np.pi * (2* i +1)) / (2* niters)) for i inrange(niters)]taus = [(lam_max + lam_min - (lam_min - lam_max) * r) /2for r in roots]x = np.zeros(n)r = A.dot(x) - rhsres_cheb_even = [np.linalg.norm(r)]#print(taus)# Implementation may be non-optimal if number of iterations is not power of twodef leb_shuffle_2n(n):if n ==1:return np.array([0,], dtype=int)else: prev = leb_shuffle_2n(n //2) ans = np.zeros(n, dtype=int) ans[::2] = prev ans[1::2] = n -1- prevreturn ansgood_perm_even = leb_shuffle_2n(niters)print(good_perm_even, len(good_perm_even))# good_perm_even = np.random.permutation([i for i in range(niters)])ts = np.array(taus)[good_perm_even]plt.figure()plt.plot(1/ts)for i inrange(niters): x = x -1.0/taus[good_perm_even[i]] * r r = A.dot(x) - rhs res_cheb_even.append(np.linalg.norm(r))plt.figure()plt.semilogy(res_richardson, label="Richardson")plt.semilogy(res_cheb_even, label="Chebyshev")plt.legend(fontsize=20)plt.xlabel("Number of iterations, $k$", fontsize=20)plt.ylabel("Residual norm, $\|Ax_k - b\|_2$", fontsize=20)plt.xticks(fontsize=20)_ = plt.yticks(fontsize=20)
Проект с открытым исходным кодом для численных вычислений (Python и Matlab интерфейсы)
Основан на численных алгоритмах, работающих с кусочно-полиномиальными интерполянтами и многочленами Чебышева
Этот проект был инициирован Ником Трефетеном и его студентом Захари Баттлсом в 2002 году, см. статью о проекте chebfun в SISC
Инструментарий Chebfun в основном фокусируется на следующих задачах
Аппроксимация
Квадратуры
Обыкновенные дифференциальные уравнения
Уравнения в частных производных
Поиск корней
Глобальная оптимизация в одномерном случае
А что есть кроме Чебышева?
Мы сделали важное предположение о спектре: он содержится в интервале на вещественной прямой (и нам нужно знать границы)
Если спектр содержится в двух интервалах, и мы знаем границы, мы также можем поставить задачу оптимизации для оптимального многочлена.
Спектр матрицы, содержащийся в нескольких сегментах
Для случая двух сегментов наилучший многочлен задается многочленами Золотарева (выраженными в терминах эллиптических функций). Оригинальная работа была опубликована в 1877 году, подробности здесь
Для случая более чем двух сегментов наилучший многочлен может быть выражен в терминах гиперэллиптических функций
Как мы можем улучшить это
Реализация ускорения Чебышева требует знания спектра.
Она хранит только предыдущий векторx_k и вычисляет новый вектор коррекции
r_k = A x_k - f.
Это относится к классу двухчленных итерационных методов, т.е. он аппроксимирует x_{k+1}, используя 2 вектора: x_k и r_k.
Оказывается, что если мы храним больше векторов, то мы можем обойтись без оценки спектра (и получить лучшую сходимость на практике)!
Ключевой момент: подпространство Крылова
Метод Чебышева производит приближение вида
x_{k+1} = x_0 + p(A) r_0,
т.е. оно лежит в подпространстве Крылова матрицы, которое определяется как
Наиболее естественный подход - найти вектор в этом линейном подпространстве, который минимизирует определенную норму ошибки
Идея методов Крылова
Идея заключается в минимизации заданного функционала: - Энергетической нормы ошибки для систем с эрмитовыми положительно-определенными матрицами (метод CG). - Нормы невязки для систем с произвольными матрицами (методы MINRES и GMRES). - Отношения Рэлея для задач на собственные значения (метод Ланцоша).
Чтобы сделать методы практичными, необходимо: 1. Ортогонализировать векторы A^i r_0 подпространства Крылова для обеспечения устойчивости (процесс Ланцоша). 2. Вывести рекуррентные формулы для уменьшения вычислительной сложности.
Мы рассмотрим эти методы подробно на следующей лекции.
Основные выводы
Основная идея итерационных методов
Итерация Ричардсона: эрмитов и неэрмитов случай
Ускорение Чебышева
Определение подпространства Крылова
Вопросы?
from IPython.core.display import HTMLdef css_styling(): styles =open("./styles/custom.css", "r").read()return HTML(styles)css_styling()